本篇文章还是跟EF性能有关,下面还是先引入需要的Model。
public class Category
{
public int Id { get; set; }
public string Name { get; set; }
public virtual List<Post> Posts { get; set; }
}
public class Post
{
public int Id { get; set; }
public string Title { get; set; }
public string Content { get; set; }
public string Url { get; set; }
public int CategoryId { get; set; }
public virtual Category Category { get; set; }
public virtual List<Tag> Tags { get; set; }
}
本文的题目查询之所需,包含2个含义。一是,查询所需要的实体对象;二是,查询所需要的属性。
1.查询所需要的实体对象
比如,现在需要查询数据,返回如下列表:
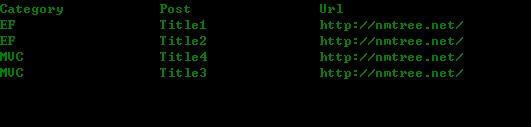
第一种方法:
var categories = ctx.Categories.Include(t => t.Posts).ToList();
WriteHeader("第一种方法");
foreach (var category in categories)
{
foreach (var post in category.Posts)
{
WriteRowData(post);
}
}
第二种方法:
var posts = ctx.Posts.Include(t => t.Category).ToList();
WriteHeader("第二种方法");
foreach (var post in posts)
{
WriteRowData(post);
}
这两种方法输出的结果是一样的,很明显,第一种方法用了2个循环才输出了结果,但是我们不关注这个,我们关注的是生成的SQL: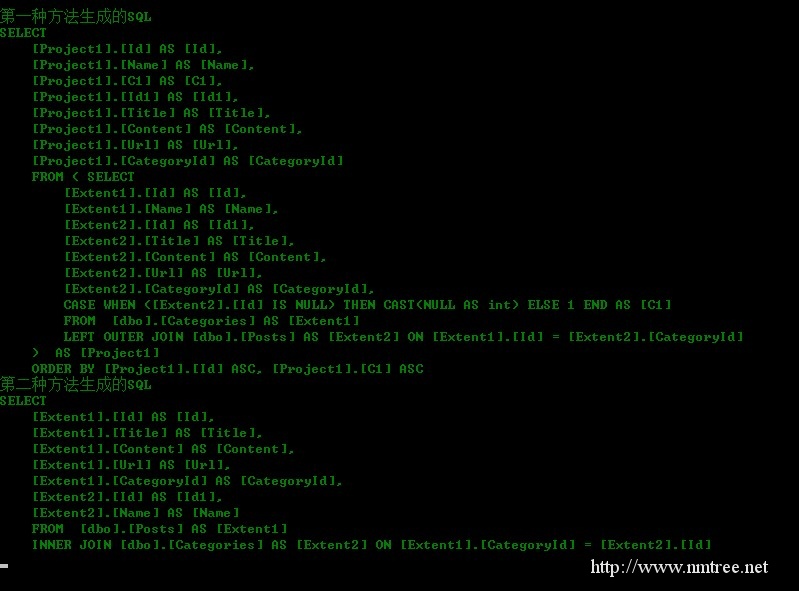
显然第二种方法生成的SQL简单很多,至于查询性能,有兴趣的可以看一下它们的执行计划。
这个地方如同SQL查询时一样,要用结果集多的表关联结果集少的表。这个地方举得这个例子,用过EF的都不会写出第一种方法的代码,但是在模型比较复杂的情况下,一定要注意这种差别带来的性能影响。
2.查询所需要的属性
上图中,第二种方法生成的SQL包含了我们需求中不需要的字段,如Content,一般情况下Content中的内容都会非常大,所以我们希望生成的SQL中不包含Content字段,那么这就是“查询所需要的属性”要完成的工作了。
EF中查询指定的字段使用扩展方法Select。
var specifyPosts = ctx.Posts.Select(t => new { t.Id, t.Title, t.Category.Name });
相应生成的SQL如下:
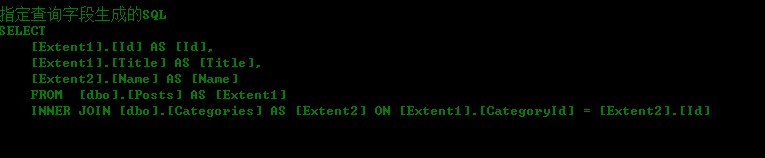
当然使用了Select,就不用再使用Include预先加载关联的实体了。
另外,使用JSON.NET序列化对象时,如果存在循环引用,默认会抛出异常,当然可以使用如下配置:
var jsSettings = new JsonSerializerSettings();
jsSettings.ReferenceLoopHandling = ReferenceLoopHandling.Ignore;
如果我们要序列的对象不存在循环引用,则同样可以使用Select.
var categories = ctx.Categories.Select(t => new { t.Id, t.Name, Posts = t.Posts.Select(s => new { s.Id, s.Title }) });
总结
本篇文章的内容很少,在用EF开发时注意一点就行了。性能是一个综合的结果,EF的优化是一方面,数据库的优化是另外一面。
本文所用源代码:链接: http://pan.baidu.com/s/1tguOQ 密码: epld



如果是做一般的开发,EF还行,如果做管理软件,有动态条件,排序,分页之类型的,最好不要选EF,EF生成的SQL太差了,性能惨不忍睹。
性能惨不忍睹?太夸张了。首先生成的SQL跟EF查询的写法有关系,EF写不好生成的SQL肯定会烂。其次,EF生成的SQL比一般开发人员写的SQL效率是要高的。
不要自己不会单手开法拉利就说法拉利不好